|
摘要:
基于上下文的離線元強(qiáng)化學(xué)習(xí)(Context-basedOMRL)通過構(gòu)建一個上下文編碼器,將收集到的上下文數(shù)據(jù)映射到任務(wù)表征,進(jìn)一步基于任務(wù)表征來自適應(yīng)的在多個環(huán)境中進(jìn)行決策。然而,在離線的情形下,任務(wù)表征的編碼器極大的依賴于用于訓(xùn)練的離線數(shù)據(jù)的豐富程度。當(dāng)數(shù)據(jù)采集有限,以至于與特定采樣策略的特點(diǎn)耦合時,學(xué)習(xí)的任務(wù)編碼器通常…
|


基于上下文的離線元強(qiáng)化學(xué)習(xí)(Context-based OMRL)通過構(gòu)建一個上下文編碼器,將收集到的上下文數(shù)據(jù)映射到任務(wù)表征,進(jìn)一步基于任務(wù)表征來自適應(yīng)的在多個環(huán)境中進(jìn)行決策。然而,在離線的情形下,任務(wù)表征的編碼器極大的依賴于用于訓(xùn)練的離線數(shù)據(jù)的豐富程度。當(dāng)數(shù)據(jù)采集有限,以至于與特定采樣策略的特點(diǎn)耦合時,學(xué)習(xí)的任務(wù)編碼器通常會難以獲得較好的泛化能力,進(jìn)而影響元強(qiáng)化學(xué)習(xí)的性能。
基于此,南京大學(xué)&南棲仙策團(tuán)隊(duì)合作提出了一種基于模型對抗樣本增強(qiáng)的環(huán)境特征編碼器學(xué)習(xí),task Representation learning via adversarial Data Augmentation (ReDA)算法,并發(fā)表在AAMAS24會議上。這一方法可以應(yīng)用于元強(qiáng)化學(xué)習(xí)的環(huán)境特征識別上,緩解了以往算法中環(huán)境特征和采樣策略耦合的影響,從而使得我們在樣本受限的實(shí)際場景中可以提升環(huán)境特征編碼器的泛化能力,進(jìn)而提高元學(xué)習(xí)策略的表現(xiàn),推進(jìn)強(qiáng)化學(xué)習(xí)在現(xiàn)實(shí)世界的應(yīng)用落地。
離線元強(qiáng)化學(xué)習(xí)環(huán)境特征耦合問題
離線元強(qiáng)化學(xué)習(xí)(Offline Meta Reinforcement Learning)是一種重要的機(jī)器學(xué)習(xí)技術(shù),其結(jié)合了離線和元學(xué)習(xí)兩種方法優(yōu)勢,可以幫助智能系統(tǒng)從以往的多種環(huán)境的離線經(jīng)驗(yàn)中學(xué)習(xí),以提高在新環(huán)境下的泛化能力。通過離線數(shù)據(jù),系統(tǒng)可以更有效地利用以往的經(jīng)驗(yàn),而無需實(shí)時與環(huán)境進(jìn)行交互,從而提高數(shù)據(jù)利用效率。并且,由于在不同的環(huán)境下進(jìn)行學(xué)習(xí),而不僅僅是在當(dāng)前環(huán)境下,也極大的提高了策略的泛化能力。
在很多實(shí)際應(yīng)用中,實(shí)時與多種環(huán)境交互收集數(shù)據(jù)可能會很昂貴或不切實(shí)際,離線元強(qiáng)化學(xué)習(xí)為這些場景提供了解決方案。離線元強(qiáng)化學(xué)習(xí)可以使強(qiáng)化學(xué)習(xí)技術(shù)更易于應(yīng)用和部署,在提高泛化能力、數(shù)據(jù)效率、穩(wěn)健性以及降低成本等方面具有重要意義,尤其是在實(shí)際應(yīng)用中,如機(jī)器人控制與路徑規(guī)劃、自動駕駛系統(tǒng)、智能游戲角色、智能物流和倉儲以及工業(yè)自動化等方面具有廣泛的用途。
離線元強(qiáng)化學(xué)習(xí)中,主要的方法是基于上下文的離線元強(qiáng)化學(xué)習(xí)。該類方法將策略建模為兩部分:第一部分是環(huán)境特征提取器,可以將歷史收集到的上下文數(shù)據(jù)映射到環(huán)境特征上;第二部分是基于環(huán)境特征的條件策略,在給定的當(dāng)前狀態(tài)和得到的環(huán)境特征的條件下進(jìn)行決策。第一部分的任務(wù)編碼器是非常重要的,提取的環(huán)境特征將直接決定了下游的元策略的學(xué)習(xí)質(zhì)量和泛化能力。
然而,以往的環(huán)境特征編碼學(xué)習(xí)需要依賴非常豐富且多樣的數(shù)據(jù)進(jìn)行學(xué)習(xí),這在很多真實(shí)的物理場景中是不現(xiàn)實(shí)甚至存在一定危險的,比如機(jī)器人等。以往的工作中,環(huán)境特征提取是基于對比學(xué)習(xí)直接在離線數(shù)據(jù)集上進(jìn)行訓(xùn)練的:
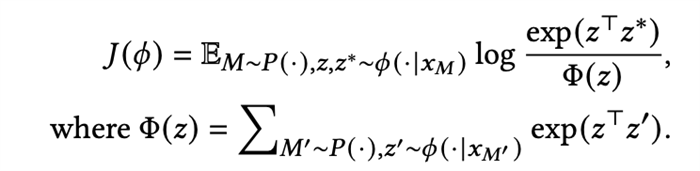
由于對比學(xué)習(xí)直觀上就是減小相同任務(wù)的上下文表征的距離,增大不同環(huán)境的上下文表征的距離,通常需要收集到非常豐富的離線數(shù)據(jù)集來獲得一個魯棒且可泛化的環(huán)境表征,例如CORRO[1]需要使用整個訓(xùn)練期間的所有策略檢查點(diǎn)來收集數(shù)據(jù),這在真實(shí)場景中是不現(xiàn)實(shí)的,顯然整個訓(xùn)練流程中的數(shù)據(jù)對于現(xiàn)實(shí)任務(wù)例如機(jī)器人控制任務(wù)是很難獲取的,甚至獲取過程中存在一定的不安全因素。因?yàn)楹芏鄷r候我們無法獲取如此豐富的樣本來訓(xùn)練一個好的環(huán)境特征編碼器,所以我們需要去關(guān)注數(shù)據(jù)集有限時環(huán)境編碼器的學(xué)習(xí)問題。
簡單以倒立桿任務(wù)(InvertedPendulum)為例,我們的訓(xùn)練數(shù)據(jù)是重力1.0下的高質(zhì)量數(shù)據(jù)和重力2.0下的低質(zhì)量數(shù)據(jù),然后使用上下文數(shù)據(jù)是1.0倍重力下的低質(zhì)量的數(shù)據(jù)進(jìn)行測試(圖1-a),對數(shù)據(jù)集的分布進(jìn)行降維可視化展示(圖1-b),發(fā)現(xiàn)測試數(shù)據(jù)到同樣環(huán)境下的訓(xùn)練數(shù)據(jù)的距離,并沒有相對其他環(huán)境的訓(xùn)練數(shù)據(jù)的距離更加接近(圖1-c),這樣的情況下,僅僅依賴于數(shù)據(jù)集的對比學(xué)習(xí),由于缺少足以代表環(huán)境任務(wù)特征的樣本,將很難保證任務(wù)表征的泛化能力。
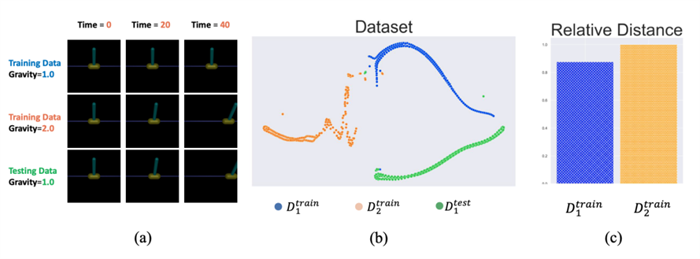
圖1. (a). 訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù) (b). 數(shù)據(jù)分布的可視化 (c). 測試數(shù)據(jù)到不同任務(wù)的訓(xùn)練數(shù)據(jù)的相對距離
基于模型的對抗樣本增強(qiáng)
為了讓環(huán)境特征編碼器更好地捕捉到環(huán)境特征而非采樣策略本身的特征,我們提出了一種基于模型的對抗樣本增強(qiáng)的方法,產(chǎn)生更多的不同于數(shù)據(jù)集的數(shù)據(jù)來訓(xùn)練環(huán)境特征編碼器。
首先我們基于每個任務(wù)的數(shù)據(jù)集,分別學(xué)習(xí)各個任務(wù)上的轉(zhuǎn)移模型:
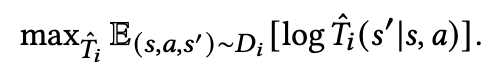
在學(xué)習(xí)好可以用來交互的環(huán)境模型后,接下來我們需要面臨的問題是:1.采集什么樣的樣本來有效增強(qiáng)任務(wù)編碼器的能力?2.如何緩解環(huán)境模型誤差帶來的影響?
對于這兩個問題,我們引入了一個對抗采樣策略,該策略的優(yōu)化目標(biāo)主要由三部分組成:
·最小辨識度的樣本:我們需要采集讓任務(wù)編碼最難區(qū)分的樣本,即該樣本到相同任務(wù)的距離和到其他任務(wù)的距離差距不大。所以我們考慮這樣的樣本需要具備的特點(diǎn)是,當(dāng)它被加入上下文之后,會導(dǎo)致基于上下文的對比學(xué)習(xí)的損失函數(shù)上升。所以我們使用該損失函數(shù)變化的程度來作為優(yōu)化的獎勵信號,如果對比損失上升越大,說明該樣本的引入使得任務(wù)編碼器更加難以識別環(huán)境了。定義該樣本加入前的任務(wù)表征為z_t,加入該樣本后的任務(wù)表征為z_t+1,單步的獎勵定義為:
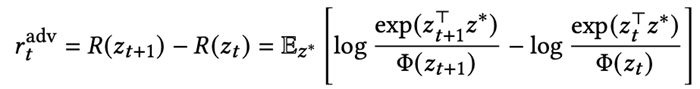
·模型不確定性懲罰:我們并不希望對抗策略去搜索模型中誤差過于大的區(qū)域,所以參考MOPO我們基于不確定性度量給出對樣本的懲罰。
·任務(wù)相關(guān)獎勵:我們使用了任務(wù)的獎勵函數(shù)來避免對抗策略去搜索和任務(wù)無關(guān)的樣本。
綜上所述,我們最終得到了在模型上搜索對抗樣本的對抗策略的優(yōu)化目標(biāo):
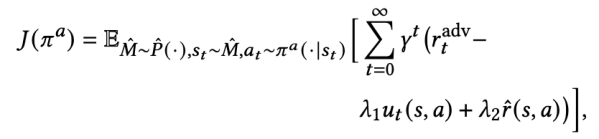
基于該對抗策略搜索到的增強(qiáng)樣本,我們得到了新的環(huán)境特征編碼器的優(yōu)化目標(biāo):
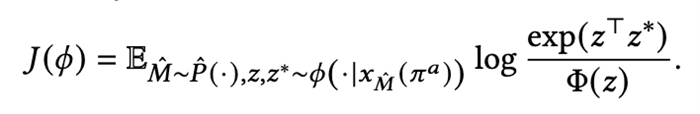
該目標(biāo)是一個標(biāo)準(zhǔn)的強(qiáng)化學(xué)習(xí)的定義,所以可以使用SAC等算法求解。
整體的算法流程如下圖所示,首先基于離線數(shù)據(jù)集學(xué)習(xí)轉(zhuǎn)移模型,然后在轉(zhuǎn)移模型上獲得對抗策略,并產(chǎn)生對抗數(shù)據(jù)訓(xùn)練任務(wù)編碼器,再基于任務(wù)編碼器訓(xùn)練最終的元策略。

圖2. 算法流程
整體訓(xùn)練的算法描述如下:

技術(shù)驗(yàn)證
基于倒立桿的環(huán)境與數(shù)據(jù)集,我們對我們的方法進(jìn)行了簡單的驗(yàn)證,首先定義相對距離:

該距離描述了相同任務(wù)下訓(xùn)練集和測試集的距離與不同任務(wù)下訓(xùn)練集和測試集的距離的差異,如果該距離越小,說明我們的表征訓(xùn)練的泛化能力越好,通過和FOCAL[2]等基礎(chǔ)算法進(jìn)行對比,我們發(fā)現(xiàn)ReDA顯著的提升了表征的泛化能力(圖3-b),并且取得了更好的測試性能(圖3-a)。這一結(jié)果表明,我們學(xué)習(xí)到的環(huán)境表征解耦了采樣的策略特征,從而更好的泛化到了更多數(shù)據(jù)上。
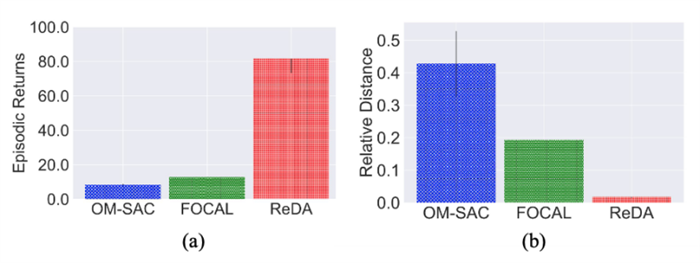
圖3. 倒立桿多種方法下的表征與性能
整體性能
我們設(shè)計了兩種模式進(jìn)行測試,第一種是on-policy模式,上下文的樣本來源于當(dāng)前策略的采樣;另一種是off-policy模式,策略來源于數(shù)據(jù)集以外的其他樣本。這兩者都是在實(shí)際部署時最常需要使用的上下文樣本,并且都存在和訓(xùn)練集存在一定的偏差。我們參考以往的工作構(gòu)建了MuJoCo上的多任務(wù)數(shù)據(jù)集,包括HalfCheetah、Hopper、Walker2d、Ant在Gravity、Dof-Damping等模擬器參數(shù)變化下的多任務(wù)數(shù)據(jù)集。在訓(xùn)練過程中我們只使用幾個檢查點(diǎn)的數(shù)據(jù),然后使用其他檢查點(diǎn)的數(shù)據(jù)作為off-policy模式下的測試數(shù)據(jù)。實(shí)驗(yàn)結(jié)果如下:
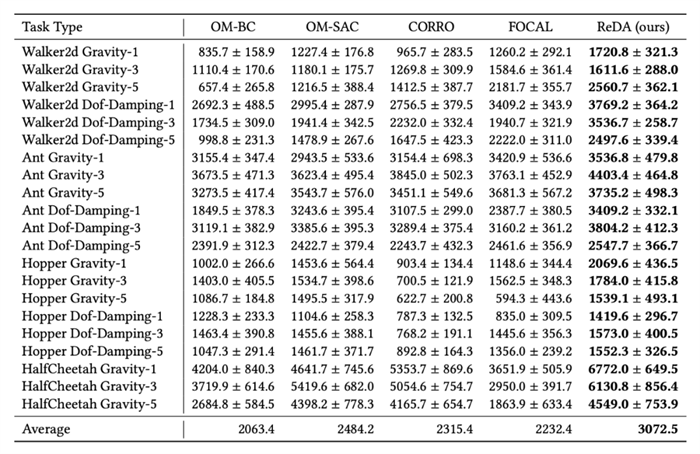
圖4. on-policy模式下的性能
其中[任務(wù)] [參數(shù)類型]-[數(shù)字]的格式表示使用的訓(xùn)練數(shù)據(jù)集是哪個任務(wù)的哪類參數(shù),總共使用了幾個檢查點(diǎn)的數(shù)據(jù)去訓(xùn)練。
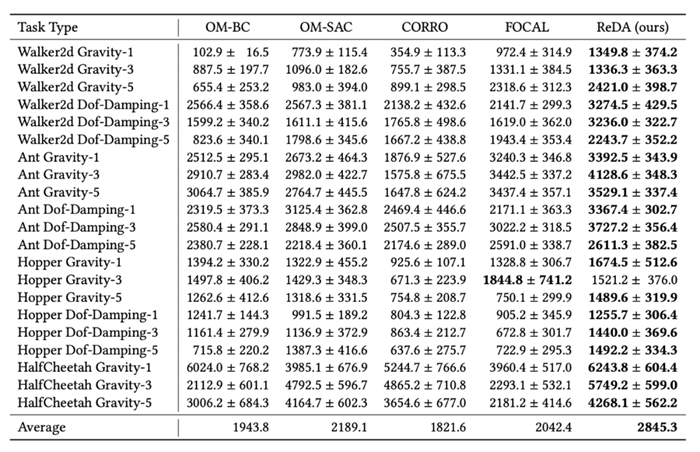
圖5. off-policy模式下的性能
其中[任務(wù)] [參數(shù)類型]-[數(shù)字]的格式表示使用的訓(xùn)練數(shù)據(jù)集是哪個任務(wù)的哪類參數(shù),總共使用了幾個檢查點(diǎn)的數(shù)據(jù)去訓(xùn)練。
可以看到,通過引入基于模型的方法,學(xué)習(xí)一個泛化能力更強(qiáng)的環(huán)境特征提取器,極大地提高了元策略的表現(xiàn),使離線元強(qiáng)化學(xué)習(xí)得以在樣本受限的情況下仍然取得一個不錯的性能。
本文關(guān)注低數(shù)據(jù)情境下的離線元強(qiáng)化學(xué)習(xí)(OMRL),強(qiáng)調(diào)了環(huán)境表示學(xué)習(xí)與數(shù)據(jù)收集策略分離的重要性,并提出了對抗數(shù)據(jù)增強(qiáng)的實(shí)際解決方案;訓(xùn)練了轉(zhuǎn)移模型和對抗性策略來增強(qiáng)離線數(shù)據(jù)集,以應(yīng)對數(shù)據(jù)集受限的情況。希望這項(xiàng)研究能夠激發(fā)對數(shù)據(jù)采樣策略在元強(qiáng)化學(xué)習(xí)中的影響,以及OMRL測試基準(zhǔn)標(biāo)準(zhǔn)化的進(jìn)一步探索。
參考文獻(xiàn)
[1]. Haoqi Yuan et al. obust Task Representations for Offline Meta-Reinforcement Learning via Contrastive Learning. (ICML 22)
[2]. Lanqing Li et al. FOCAL: Efficient Fully-Offline Meta-Reinforcement Learning via Distance Metric Learning and Behavior Regularization. (ICLR 21)
|

